 开发文档-2
开发文档-2
# V2.6【大更新】
更新点主要有
- 搜索功能
- 事件总线
# 搜索功能
搜索功能对外提供问题搜索能力,其原理是基于Lucence开发中文文本分析器,将文本分析结果输入Lucence后,构建倒排索引,从而加快搜索能力,下图则是搜索模块实现的功能预览图

有关更详细的信息,可以参考笔者的这篇文章:基于Lucence开发一个中文分析器 (opens new window)
有关搜索功能的相关代码,都存放在search包下
下面通过gif的方式介绍中文分析器的整体工作流程

- step1:数据管理模块加载分段数据
- step2:分词处理器迭代处理分段数据
- step3:分段数据处理完成,跳转至step1
- step4:所有数据加载完毕,终止处理
通过上图我们可以发现,整个处理流程可以划分为两个模块
- 数据管理模块
- 分词处理模块
# 模块整体设计
下图为笔者的模块设计图
# 数据管理模块
# SourceManager
SourceManager(简称SM),负责维护数据源source,同时管理分段数据SourceBuffer(简称SB)。对外通过迭代器,提供底层数据的访问
SM封装了底层对于数据的管理,当迭代到分段数据的边界时,会自动进行分段数据的加载。为了实现这一功能,SM封装了两个迭代器,IteratorAdvance和CaptureIterator。
# SourceBuffer
SourceBuffer,维护分段数据,SM从soure中读取的分段数据会写入SB,SB内部维护迭代器Itr,通过Itr的迭代来对外提供底层数据的访问。需要注意的是,凡是被Itr迭代过的数据,都会被SB视为已消费,被消费过的数据不会被重复访问
# IteratorAdvance
IteratorAdvance增强迭代器(简称ItrAdv),是对SB的Itr的增强。ItrAdv和Itr共同继承com.xhf.leetcode.plugin.search.Iterator接口,拥有迭代数据的能力。但ItrAdv本身并不能对SB的数据进行迭代。ItrAdv通过持有Itr,使用Itr来间接迭代SB。如果ItrAdv发现SB数据被迭代完后,ItrAdv会自动加载分段数据,从而屏蔽消费者对分段数据的感知。ItrAdv的增强设计参考了Spring的Aop,可以认为ItrAdv对Itr的增强属于AOP的环绕增强,只不过AOP运用的是反射机制,ItrAdv使用的是组合模式
# CaptureIterator
CaptureIterator快照迭代器(简称CI),是为了应对中文分词处理边界数据遇到的问题而引入的解决方案,CI迭代到边界数据时会触发SM的预加载机制,配合PreBuffer避免影响底层的SB数据。
有关CI引入的详细原因,SM的预加载机制等细节,可参考项目代码中的注释信息,本文从宏观的角度做出整体介绍
所谓快照迭代器,顾名思义,是对底层SB维护的Itr的一种快照。通过拍摄快照的形式,CI允许消费者获取SB数据的同时,不会真正消费SB内部的数据。当CI迭代到SB维护分段数据的边界时,会自动加载数据。如果数据写入SB,则SB内未被真正消费的数据会被覆盖,因此引入预加载机制。所谓预加载机制,就是将数据写入PreBuffer内,从而避免对底层数据造成修改

引入PreBuffer可以避免CI对底层数据的加载,但PreBuffer的出现会导致source内部的指针偏移,提前将SB要加载source的那部分数据加载完。因此在后续迭代的过程中,SM需要协调PreBuffer,SB,source三者之间的数据流转的问题
# 分词处理
# Segmentation
分词器,本身不负责分词,通过调用Processor对外提供分词能力。可以说Segmentation是个中转站,本身不具备各种能力。但他内部维护各种类,通过协调各个类之间的关系,从而对外提供分词能力
# Context
context,上下文对象,简称ctx。ctx内部存储分词处理过程中的上下文数据。下方为ctx的源码
public class Context {
private final SourceManager sm;
// 当前处理的字符
private char c;
// 迭代器
private Iterator iterator;
// tokens
private final Queue<Token> tokens = new LinkedList<>();
}
public class Token {
// 当前文本处理得到的token
private String token;
// 当前处理的字符长度(等于处理的字符次数)
private int len;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
需要注意的是,ctx内部采用队列维护Token。这种数据结构允许Processor在单轮处理中,产生多个合法Token
# ProcessorFactory
工厂,简称PF,通过工厂模式屏蔽创建实现类的复杂度。该工厂通过当前迭代的字符类型,判断需要创建何种处理器(Processor)
# ENProcessor
字母处理器,专门负责处理字母分词。其内部处理逻辑为,以字符c为开始,尽可能匹配长的字母。
比如遇到如下数据['h', 'e', 'l', 'l', 'o', '2', '3'],加入当前处理到的字符c为'h',那么ENP会尽可能长的将以'h'开头的字符组成的EN_Token全部匹配,最终返回EN_Token是"hello",遇到'2'后终止匹配
# DigitProcessor
数字处理器,专门负责处理数字。其原理和ENProcessor类似,都是尽可能长的匹配数字,当遇到无法组成数字的字符时,终止匹配
# NonProcessor
未知处理器,该处理器有些特殊,专门负责那些无法识别的字符。下方是该类的源码,当遇到无法处理的字符时,NonP会持续迭代数据,直到遇到能够被PF识别的字符
public class NonProcessor implements Processor {
/**
* 当前processor处理无法识别的内容. 处理逻辑为持续迭代context数据, 直到迭代出能够识别的字符, 如果没有额外数据, 则会终止迭代
* @param context
*/
@Override
public void doProcess(Context context) {
ProcessorFactory pf = ProcessorFactory.getInstance();
while (context.hasNext()) {
context.nextC();
Processor processor = pf.createProcessor(context);
// 如果下一个字符数据能被工厂识别, 则进行处理
if (! (processor instanceof NonProcessor) ) {
processor.doProcess(context);
// 完成处理, 终止运行
return;
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# CNProcessor
专门处理中文的处理器,采用最长匹配 + 最细粒度匹配。
CNProcessor会以每一个中文字符为start, 尝试以该字符为start, 匹配出最长的词组CN_Token。如果匹配得到的CN_Token长度大于1, 则同时将start作为单独的Token进行存储
比如[两, 数]: 以'两'为start可以匹配出的最长Token是'两数'. 两数的长度为2, 所以CNProcessor会存储'两数', '两'这两个Token
其内部通过DictTree来判断字符能否组成CN_Token。
# DictTree
DictTree,简称DT,字典树。通过树形结构维护词组数据,最终产生形如下方的多叉树
 每一个字符最为树的节点,并且拥有若干个后记节点。除此以外,每个节点都表示当前字符是否能够成为已有词组的最后一个字符
每一个字符最为树的节点,并且拥有若干个后记节点。除此以外,每个节点都表示当前字符是否能够成为已有词组的最后一个字符
比如说"天天开心"的'心'字,他就能成为最后一个字符。但第二个'天'字,就不行。CNP就是通过判断匹配的字符能否成为结尾来判断是否能组成合法CN_Token
# 事件总线
废弃原本的设计方式,直接使用guava包的EventBus。
另外,项目中引入了更多的事件,将原本耦合的模块彻底解耦
# V3.5.0【大更新】
- Debug服务:支持leetcode核心代码的调试,无需用户做出任何更改,风格类似idea的debug风格
- Java Debug服务
- Python Debug服务
- C++ Debug服务
Debug服务内容很多,本文仅从宏观的角度做出介绍,有关debug服务的详细介绍,可以参考我写的五篇文章+源码注释
《leetcode-runner》如何手搓一个debug调试器——引言 (opens new window)
《leetcode-runner》【图解】【源码】如何手搓一个debug调试器——架构 (opens new window)
《leetcode-runner》如何手搓一个debug调试器——指令系统 (opens new window)
《leetcode-runner》【图解】如何手搓一个debug调试器——调试程序【JDI开发】【万字详解】 (opens new window)
《leetcode-runner》【图解】【源码】如何手搓一个debug调试器——表达式计算 (opens new window)
tip: 以上五篇文章仅仅介绍Java Debug服务+整个架构的引入+可复用的内容介绍。Python,C++的将在本文介绍
# 整体架构
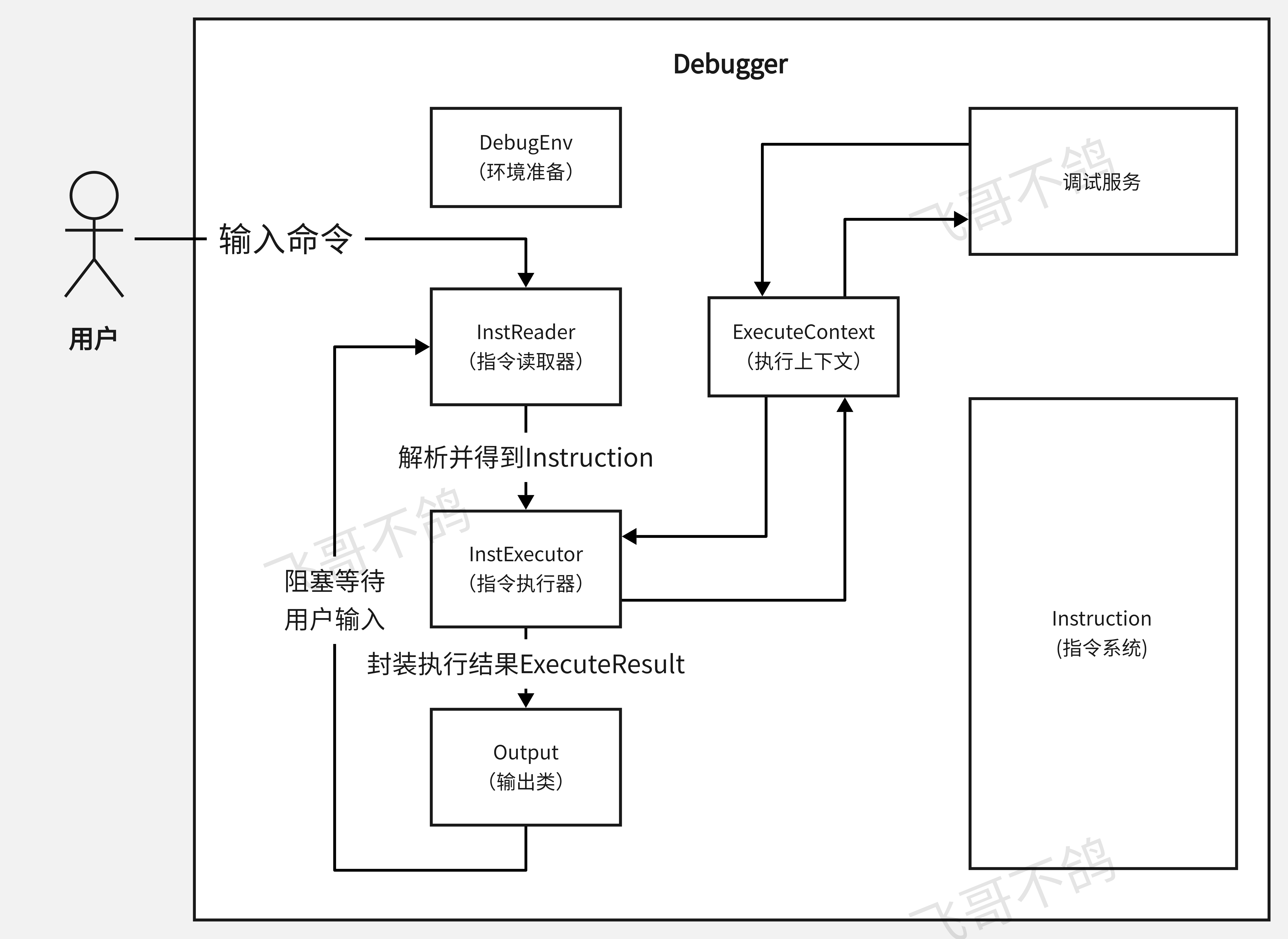
Debugger是所有debug框架的启动核心类,其中封装了所有的debug逻辑
DebugEnv是环境对象,用于构建Debug所需要的环境
Instruction代表debug框架的指令体系,每条指令对应着不同的执行逻辑
InstReader、InstExecutor、Output是整个debug流程的核心。分别负责读取指令, 执行指令, 输出执行结果
其中InstExecutor负责和核心的调试服务沟通,ExecutorContent是上下文对象,用于沟通执行器和调试服务。同时,上下文对象还能够沟通不同的指令执行器
调试服务,是整个框架最为核心的部分,它封装底层不同语言提供的调适能力,并进行代码控制,与Java插件进行交互
当前所有语言的Debug调试器均基于上述架构,后续如果需要新增不同语言的调试器,只要调试服务可以实现,那么这个语言就具备接入Leetcode-runner的能力
# Java调试服务
# 1.执行流程
Java的debug调试,核心借助JDI提供的各种接口,来实现对底层JVM的控制
有关JDI提供的接口内容,可自行查阅文档,或者阅读我的这篇文章——《leetcode-runner》【图解】如何手搓一个debug调试器——调试程序【JDI开发】【万字详解】 (opens new window)
JavaDebugger采用多线程的方式处理,其中JavaDebugger负责和用户交互,JEventHandler负责和Debug的JVM交互
其具体的执行流程可以用下图表示
其中JavaDebugger、JEvenHandler分别属于不同的线程
之所以采用多线程,是为了避免死锁的出现,有关死锁发生的场景,将会在后文介绍
# 2.死锁
死锁会发生在如下场景
假设只有单线程,那么如下情况会发生死锁
- JavaDebugger调用
Value.invokeMethod,阻塞等待执行结果,同时TargetVM恢复运行 - TargetVM运行时会产生Event返回,交由JavaDebugger捕获
- TargetVM执行产生一次Event后会暂停线程,等待被JavaDebugger放行
- JavaDebugger依赖于TargetVM返回结果,TargetVM想返回结果,依赖于JavaDebugger放行(恢复线程),因此发生死锁
如果引入多线程,那么TargetVM依赖于JEventHandler放行,自然就不会出现死锁问题
不过需要注意的是,JEventHandler争对Value.invokeMethod需要做出特殊判断
Value.invokeMethod方法会要求TargetVM重新执行一次方法,在此期间会产生大量的Step Event(单步执行事件)
JEventHandler捕获Step Event,默认不会放行,这适用于绝大多数情况。但如果JavaDebugger执行Value.invokeMethod,则需要放行,否则TargetVM无法计算得到结果
# 3. 并发问题
因为多线程的引入,自然而然的会导致并发问题。具体来说,前台JavaDebugger在使用Context的数据时,后台JEventHandler线程对其进行更改,导致前台执行得到错误的数据
为了解决这一问题,在Context中引入协调器的概念
之所以产生并发问题,本质上是因为前台执行时,后台也在执行。而协调器的引入,则让JavaDebugger等待JEventHandler稳定后,再使用Context的数据并计算,从而避免后台线程更改数据时执行计算
# 4. 表达式计算
表达式计算,允许用户在debug过程中监控某些变量,或者对变量进行额外操作,或者调用方法提前计算
在JavaDebugger中,JDI底层并没有提供相应的计算功能,因此表达式计算功能是由Leetcode-runner实现。
有关表达式计算的详细内容,可以阅读我的这篇文章《leetcode-runner》【图解】【源码】如何手搓一个debug调试器——表达式计算 (opens new window)
在Leetcode-runner中,表达式被分为以下几种类型
- 纯变量(如a,b,c这种单纯变量)
- 数组(如arr[0])
- 表达式计算(如1+2,a+b这种)
- 实例方法调用(如demo.invoke())
- 纯方法调用( dfs(),takeLocalValue(a) )
- 纯常量(如1,3.14,“nihao”, ‘&’)
- 运算符(如+,-,*,/,<<,&等)
每种类型的表达式都会被对应的对象封装,同时对外提供统计的接口,用于提供计算结果,在Leetcode-runner种,Token封装表达式内容+表达式计算功能
TokenFactory负责识别表达式并返回Token,而TokenFactory的识别依赖于内部封装的Rule
Rule封装了表达式的识别逻辑,不同的Rule对应不同的Token,且只对应一个
对于复杂的表达式,可以通过TokenFactory解析得到Token,Token内部再通过TokenFactory递归解析,逐步拆解复杂表达式,将其拆分为若干简单表达式的组合,最终计算得到结果
架构图:
上述架构以及对应的功能已经能够解决计算绝大多数复杂的表达式,诸如arr[b.invoke(1 + 2, c, arr2[0])] + dfs(1,2,c.invoke())
它就可以按照如下规则拆分:
在计算表达式当中,存在一个数组表达式arr[...],和纯函数调用表达式dfs(...)
在数组的维度信息中,存在一个方法调用表达式——a.invoke(...)。方法调用的内部,又可以拆分为计算表达式1+2,纯变量表达式c,数组表达式arr2[0]
在纯函数调用的括号内,存在两个纯常量表达式——1,2,存在一个方法调用表达式c.invoke()
尽管计算框架依然具备很强的计算逻辑,但它对于链式调用的Token依然束手无策,如a.invoke().c[0][1]
因此,再最新版本种,引入了链式调用这一概念——TokenChain
在leetcode-runner中,额外引入TokenChain,RuleChain。专门处理链式的计算
有关链式调用的详细介绍,可以参考我的这篇文章——《leetcode-runner》【图解】【源码】如何手搓一个debug调试器——表达式计算 (opens new window)
# Python调试服务
因为python和Java分属于不同语言,无法再同一个进程内运行,因此采用web的方式沟通
架构图:

后续的C++Debug服务,整体架构类似于python,往后只要是需要接入Leetcode-runner的调试器,基本都会遵循如上架构
python的debug功能,主要基于sys.settrace方法,该方法会在python解释一行代码后,自动调用传入的回调函数。而所有的debug逻辑都写在回调函数内
另外,python内置的eval函数就具备表达式计算的功能,无需手动实现
# Cpp调试服务
Cpp调试服务,底层debug能力是由GDB提供。GDB的MI模式,会返回格式化数据,方便开发者解析
但是GDB并不能直接嵌入Leetcode-runner,因为它存在一个致命的缺陷——读取、输出都是工作在终端
GDB从标准输入读取数据,然后在标准输出显示数据,但在leetcode-runner中,不存在终端。这也是为什么Java、Python等debug服务都没有封装已有的调试器
但C++不同,C++具有管道、重定向等逆天功能,它可以手动控制GDB的输入输出,使其嵌入项目当中
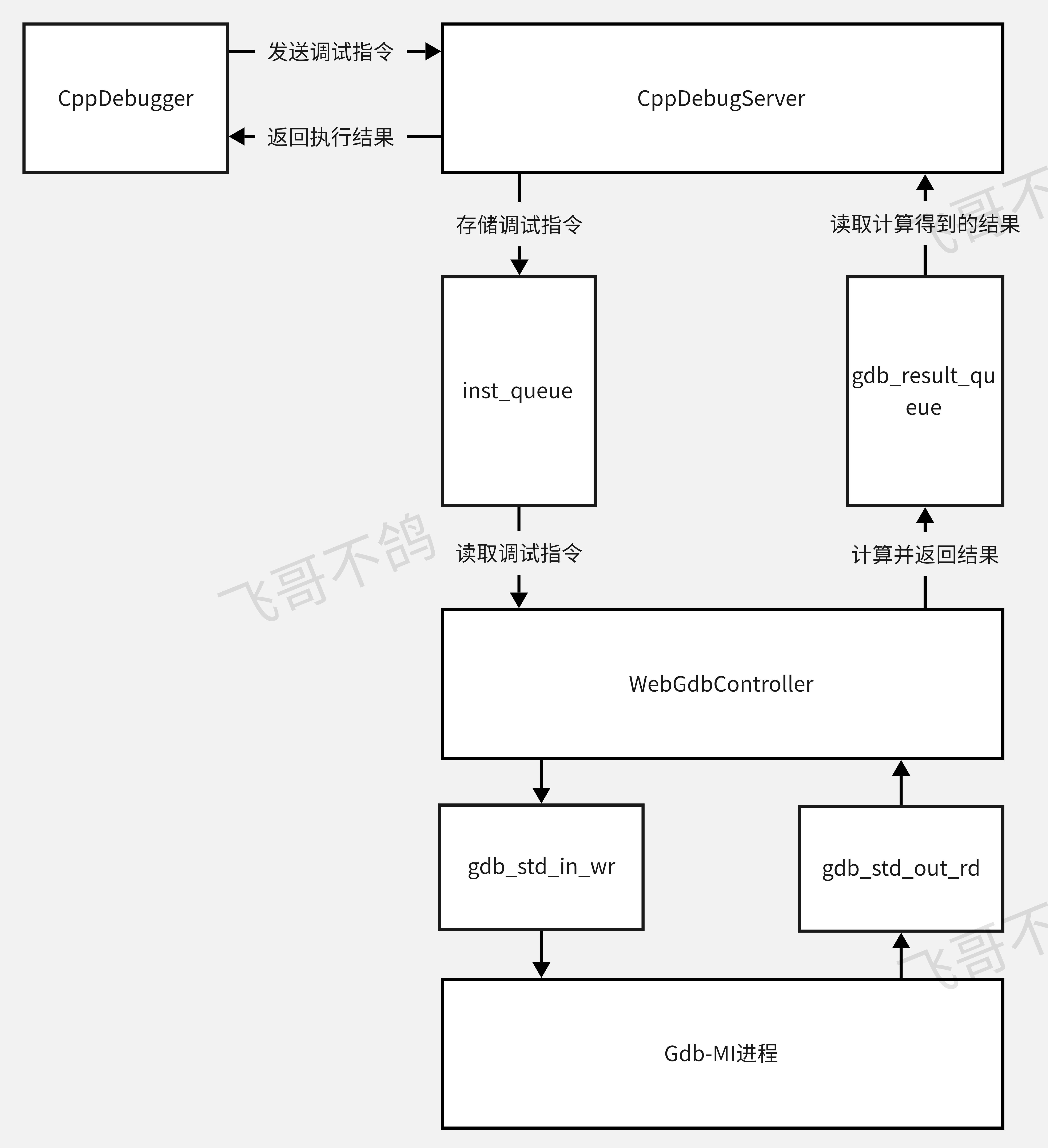
对于GDB-MI模式下输出的内容,全部交由JavaDebugger解析
解析工作由GdbParser负责,整套GDB解析学习了Gson的设计方式,整体不算复杂,但还是挺有意思的,更详细的内容请参考源码